How CNN-based Detector Helps to Solve Computer Vision Tasks
The possibility of widespread application of autonomous vehicles has been significantly increased with the extensive research on Intelligent Transport Systems-based communication and management protocols. Pedestrians are essential transportation participants, and their safety is non-negotiable. Pedestrian detection is one of the methods to protect the pedestrians’ safety, which has a wide range of application requirements and can be applied to driver assistance systems and autonomous vehicles.
In the area of pedestrian detection, deep learning-based pedestrian detection methods have gained significant development since the appearance of powerful GPUs. A large number of researchers are paying efforts to improve the accuracy of pedestrian detection by utilizing the Convolutional Neural Network (CNN)-based detectors.
My Masters’ research topic was to using deep learning methods to improve the performance of pedestrian detection to support autonomous driving. Our research work has been published to 25th IEEE Symposium on Computers and Communications (ISCC), and the slide presentation of this published conference paper can be found at here. In our paper, we proposed a one-stage anchor-free pedestrian detector named Bi-Center Network (BCNet), which is aided by the semantic features of pedestrians’ visible parts. In this post, I will walk you through the idea of our CNN-based pedestrian detector.
What does the detector do?
In the field of computer vision, machines are different from people who can directly perceive images. They only have the value of each pixel of an RGB image. The object detector has two main objectives, which are to understand what kind of target is in the image and where the target is. Therefore, it includes two tasks: classification and localization. Pedestrian detection is an application of object detection, which is mainly used to help autonomous driving systems to ensure driving safety. Here is a demo of pedestrian detection. The pedestrian detector will draw a bounding box to indicate the location of the pedestrian, and will also predict the confidence score a the meanwhile. Here is a detection demo:

Our Detector Pipeline
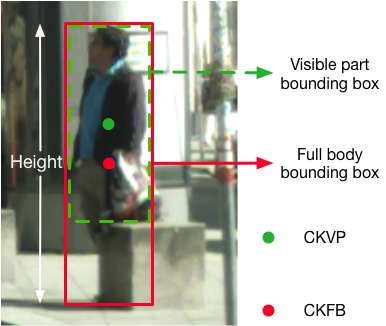
In our work, we proposed a pedestrian detector called Bi-Center Network (BCNet), which utilized the fused semantic feature of the center keypoint of the full body (CKFB) and the center keypoint of the visible part (CKVP) of each pedestrian.
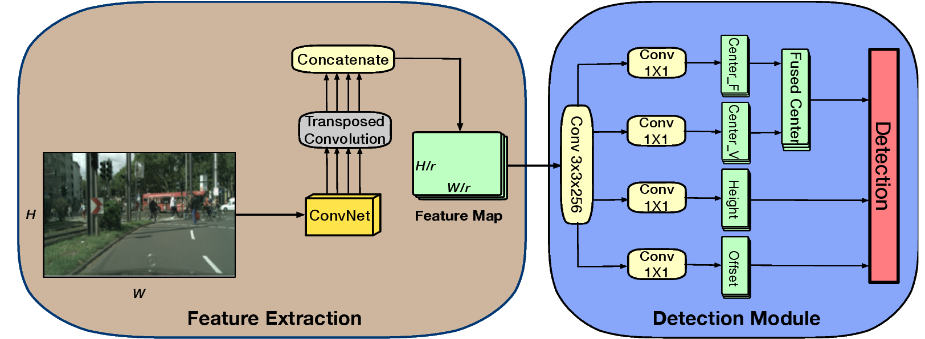
The framework of our BCNet has two main modules: the feature extraction module produces the concatenated feature maps that extracted from different layers of ResNet, and the four parallel branches in the detection module produce the full body center keypoint heatmap, visible part center keypoint heatmap, heights, and offsets, respectively. The final bounding boxes are converted from the high response points on the fused center keypoint heatmap and corresponding predicted heights and offsets.
The model proposed in this paper takes CSP as the baseline model. One drawback of CSP is that it does not take advantage of the visible part feature for each pedestrian. In the proposed network, we introduce a heatmap for the center keypoint of the visible part. We use ResNet-50 structure in ConvNet to extract different levels of features. Because ResNet uses a bypass design, which greatly improves the accuracy of the deep network. The feature map from ConvNet’s deeper layers has a lower resolution but a higher semantic level. To take advantage of the high resolution and high semantic feature, we extract multi-scale feature maps from conv2_x layer, conv3_x layer, conv4_x layer, and conv5_x layer in ResNet-50. The feature maps from different layers are de-convolutioned and concatenated. Before concatenating together, we rescale four feature maps to the same size by using the transposed convolution layers.
The generated final feature map is of size H/r x W/r, where H and W are the height and width of the input image, and r = 4 is the downsampling ratio suggested in other papers. In our model, after reducing the feature map channel from 1024 to 256 by a 3 x 3 Conv layer, our detector has four parallel branches. These four branches are processed by four separate 1 x 1 Conv layers and the parameters of the four subnets are not shared. To generate the final prediction, we fuse the CKFB and CKVP to obtain the fused center keypoints, and we predict the height of each pedestrian. We also predict the offsets of the center keypoints to fine-tune the position of center keypoints.
Experiments and Improvements:
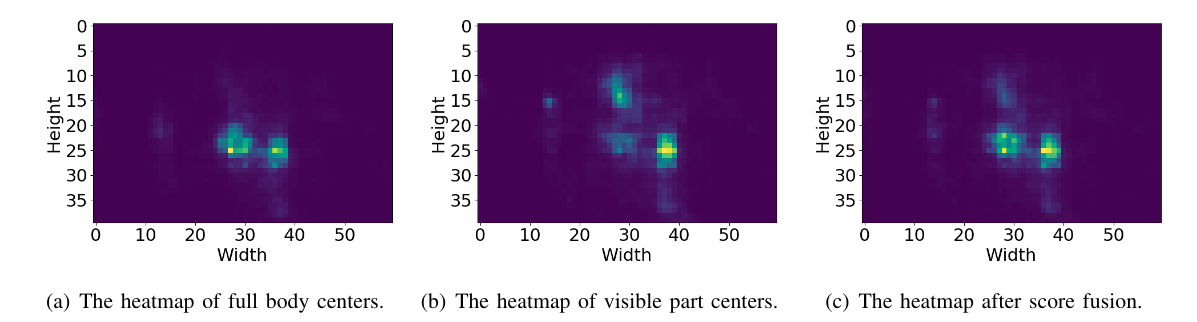
Compared with the accuracy of the baseline model, our BCNet improved by 2%. The experimental results indicate that the performance of pedestrian detection could be significantly improved because the visibility semantic could prompt stronger responses on the heatmap. We compare our BCNet with state-of-the-art models on the CityPersons dataset and ETH dataset, which shows that our detector is effective and achieves a promising performance.
Tools:
The image data and annotations are processed with NumPy, Pandas, and Pillow. We implement our detectors and other baseline models with PyTorch, Tensorflow, and Keras. We perform experiments on the CityPersonsd dataset and the ETH dataset.
